Research Projects | Overview
Learn about our current research projects:
- Intelligible Predictive Health Models
- Fair Machine Learning for Health Care
- Automating Digital Health
Intelligible Predictive Health Models
We study both black-box and glass-box ML methods to improve the intelligibility and/or explainability of models that are trained for clinical prediction tasks using electronic health record (EHR) data. Despite their promise, EHR data are difficult to use for predictive modeling due to the various data types they contain (continuous, categorical, text, etc.), their longitudinal nature, the high amount of non-random missingness for certain measurements, and other concerns. Furthermore, patient outcomes often have heterogeneous causes and require information to be synthesized from several clinical lab measures and patient visits. Researchers often resort to using complex, black-box predictive models to overcome these challenges, thereby introducing additional concerns of accountability, transparency and intelligibility.
Explaining black-box models
Our empirical work with predictive health models suggests that, although black-box models are typically accurate, they are often bad at explaining how they arrive at those predictions, and may also disagree with very similar models about which factors are driving their predictive ability [1].
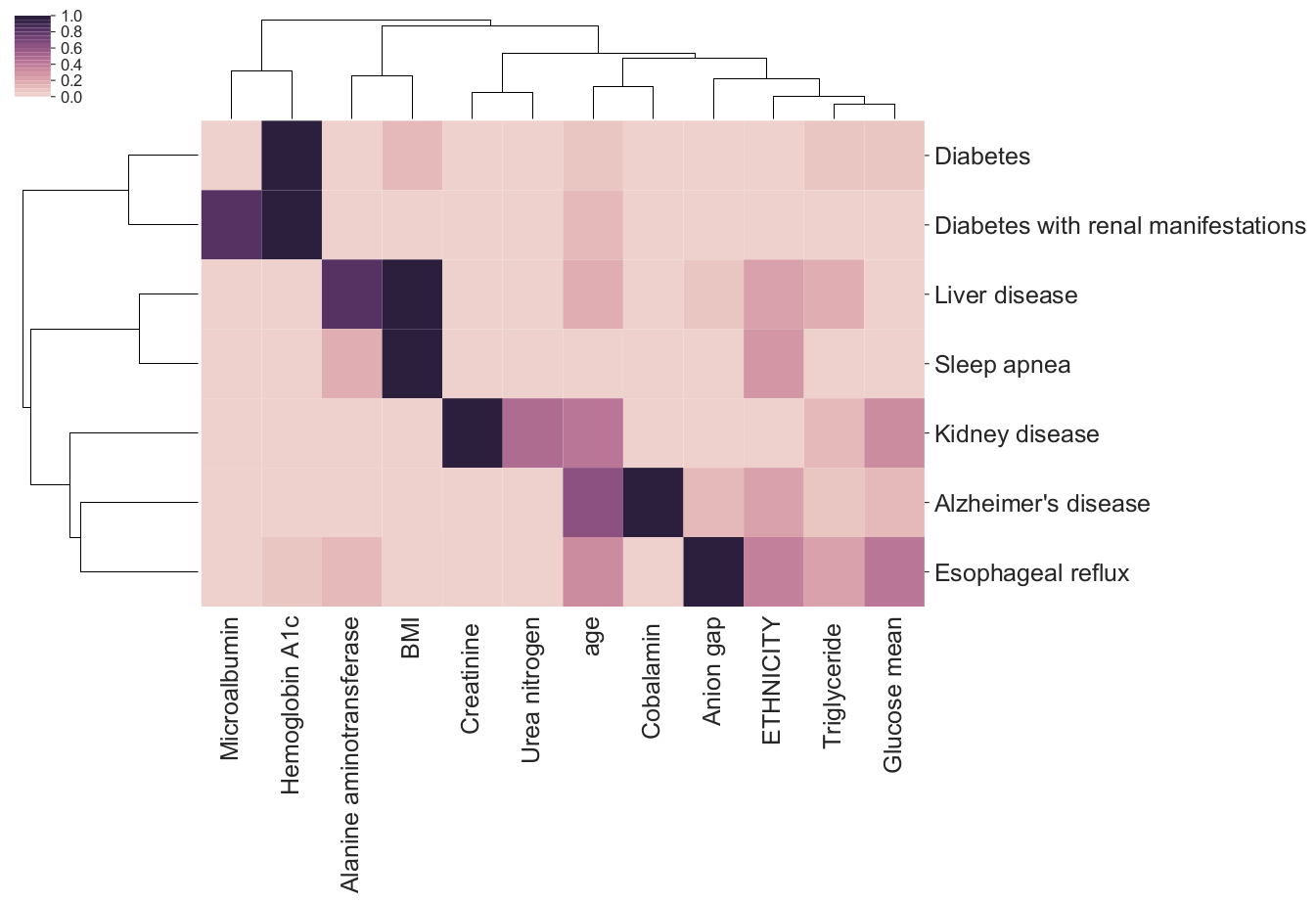
Feature importance bi-clustering across diseases and predictors
Symbolic regression for interpretable machine learning
An alternative, and promising approach, is to use glass-box ML methods such as symbolic regression that can capture complex relationships in data and yet produce and intelligible final model. Symbolic regression methods jointly optimize structure of a model, as well as its parameters, usually with the goal of finding a simple and accurate symbolic model.
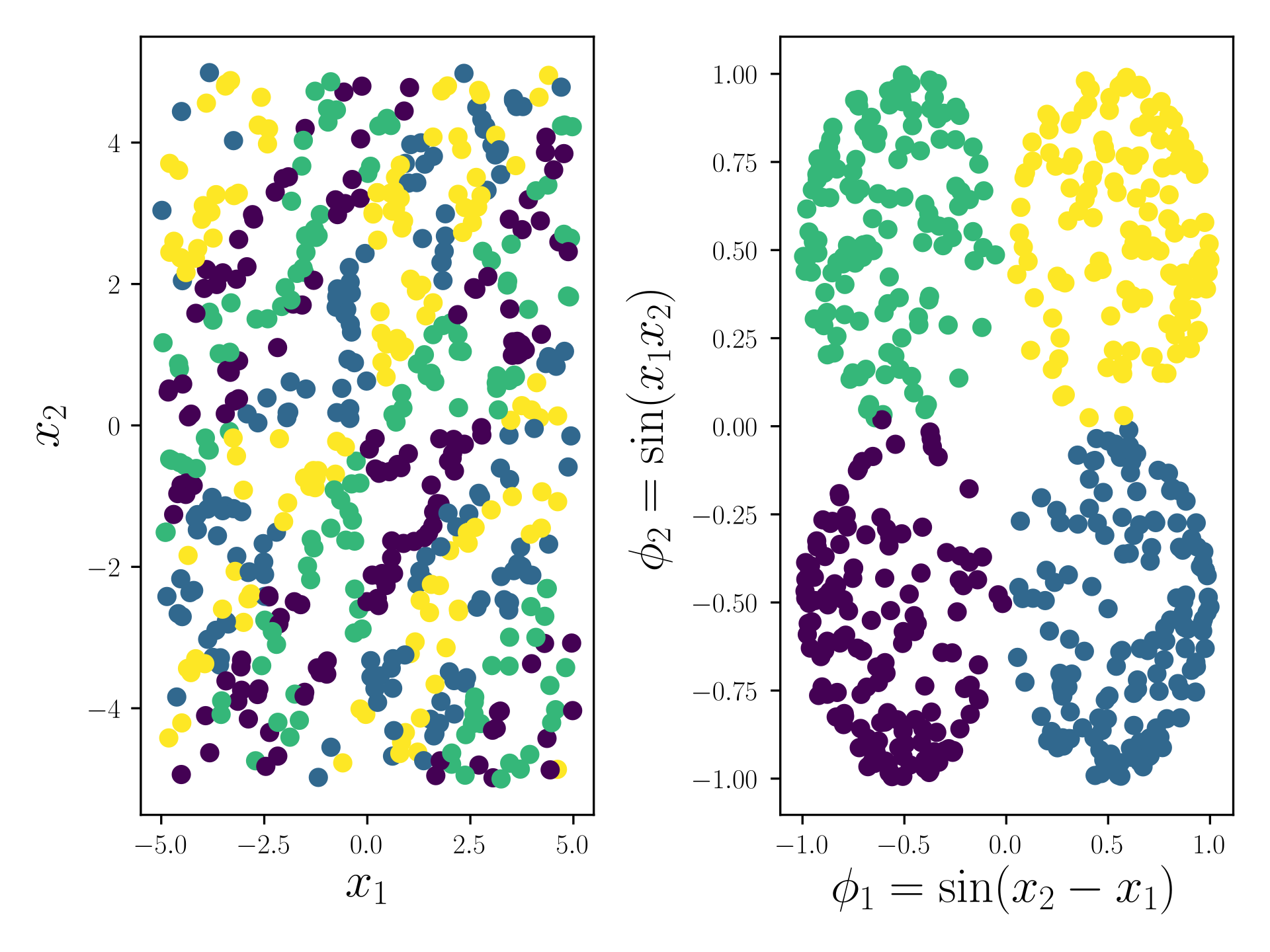
An example representation from the Feat docs
Through extensive, international benchmarking efforts [2], we have found that, for many tasks, symbolic regression approaches can perform as well as or better than state-of-the-art black-box approaches - and still produce simpler expressions.
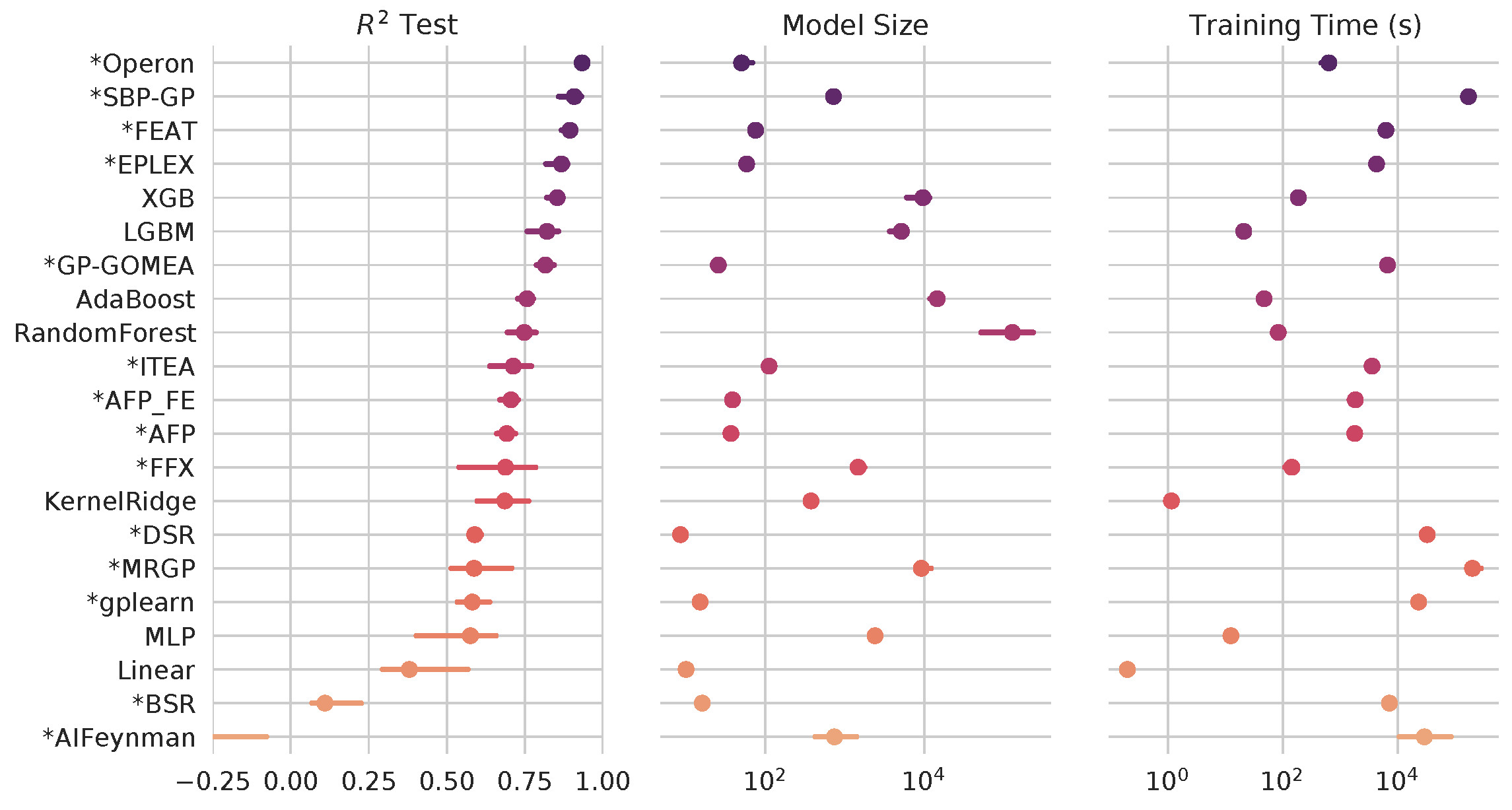
Symbolic regression algorithms (marked with asterisk) benchmarked against black-box ML on hundreds of regression problems. See more at https://github.com/EpistasisLab/srbench
Automatically generating interpretable and accurate clinical phenotypes
Our preliminary work on symbolic regression approaches to patient phenotyping have shown success in producing accurate and interpretable models of treatment resistant hypertension [3]. Our lab is working to scale and study these algorithms in routine clinical care.
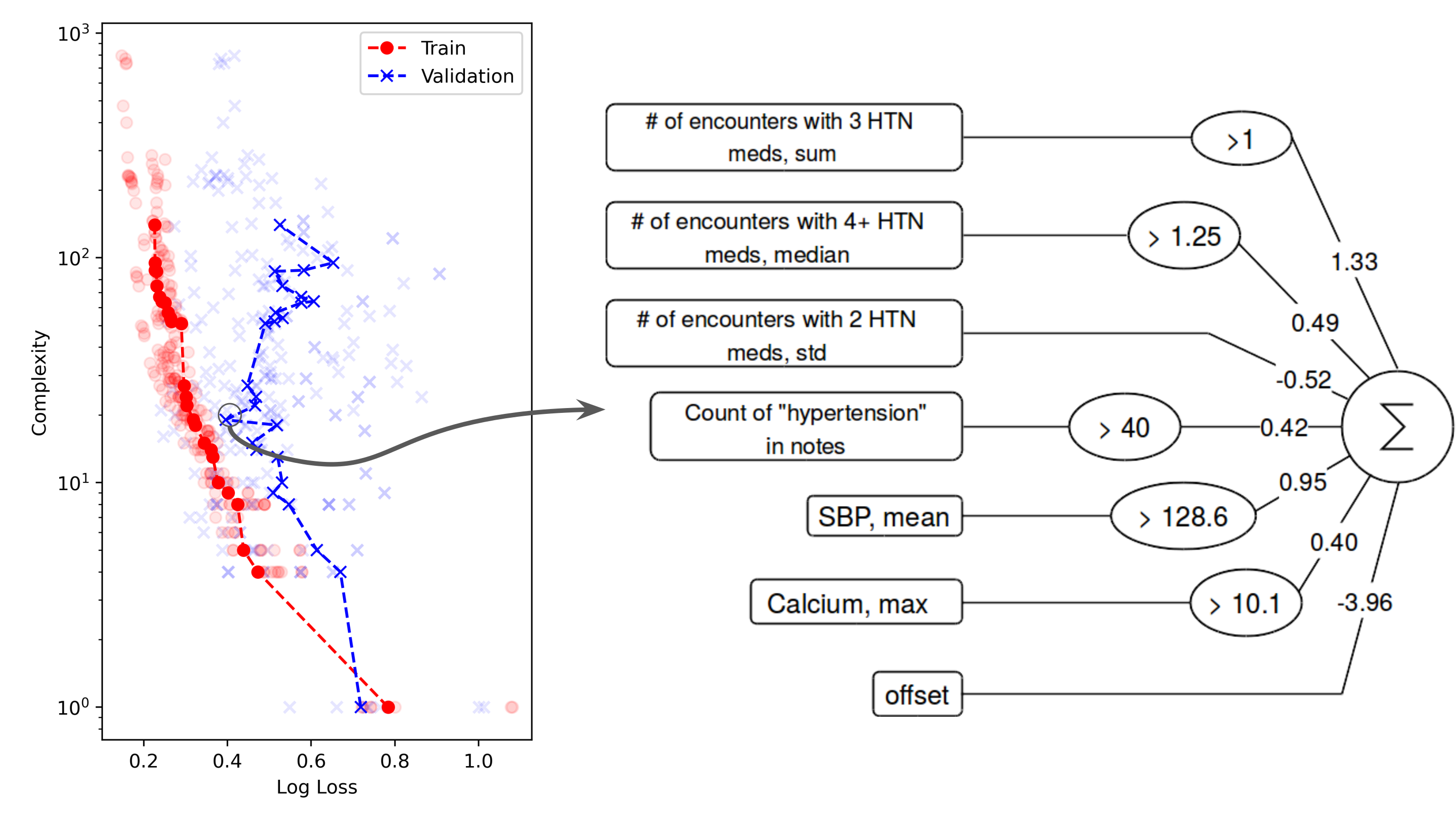
A symbolic regression model of treatment resistant hypertension
Relevant work:
1. La Cava, W., Bauer, C. R., Moore, J. H., & Pendergrass, S. A. (2019). Interpretation of machine learning predictions for patient outcomes in electronic health records. AMIA 2019 Annual Symposium. [arXiv]
2. La Cava, W., Orzechowski, P., Burlacu, B., França, F. O. de, Virgolin, M., Jin, Y., Kommenda, M., & Moore, J. H. (2021). Contemporary Symbolic Regression Methods and their Relative Performance. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. [arXiv] [project repository]
3. La Cava, W., Lee, P.C., Ajmal, I., Ding, X., Cohen, J.B., Solanki, P., Moore, J.H., and Herman, D.S (2021). Application of concise machine learning to construct accurate and interpretable EHR computable phenotypes. [medRxiv]
Fair Machine Learning for Healthcare
When deployed in healthcare settings, it’s important that models are fair - i.e., that they do not cause harm or unjustly benefit specific subgroups of a population. Otherwise, models deployed to assist in patient triage, for example, could exacerbate existing unfairness in the health system. There are many ways in which predictive health models can recapitulate and/or exacerbate systemic biases in treatment and outcomes. The field of fair ML provides a framework for requiring a notion of fairness to be maintained in models generated from data containing protected attributes (e.g. race and sex). What fairness means – perhaps equivalent error rates across groups, or similar treatment of similar individuals – varies considerably by application, and inherent conflicts can arise when asking for multiple types of fairness. Furthermore, there is a fundamental trade-off between the overall error rate of a model and its fairness (c.f. Fig. 1B here), and it is an open question how to best characterize and present these trade-offs to stakeholders in the health system. For example, we might want to prioritize fairness heavily in an algorithm used in patient triage, but weigh error rates more when predicting individual treatment plans and outcomes. Due to combinatorial challenges, fair models are hard to learn and audit when considering intersections of protected attributes (e.g. black males over 65). Thus, two open questions are how to best define the metrics for assessing intersectional definitions of fairness, and how to approximately satisfy them.
Our lab focuses on addressing these challenges by developing flexible search methods that can explicitly optimize multiple criteria - in this case, between model accuracy and fairness. We are interested in understanding the intricacies of downstream impacts on healthcare that will arise as more and more models are deployed in the health system. Providing a set of models (e.g. above) varying in fairness and accuracy is one way to aid a decision maker in understanding how an algorithm will affect the people it interacts with when it is deployed.
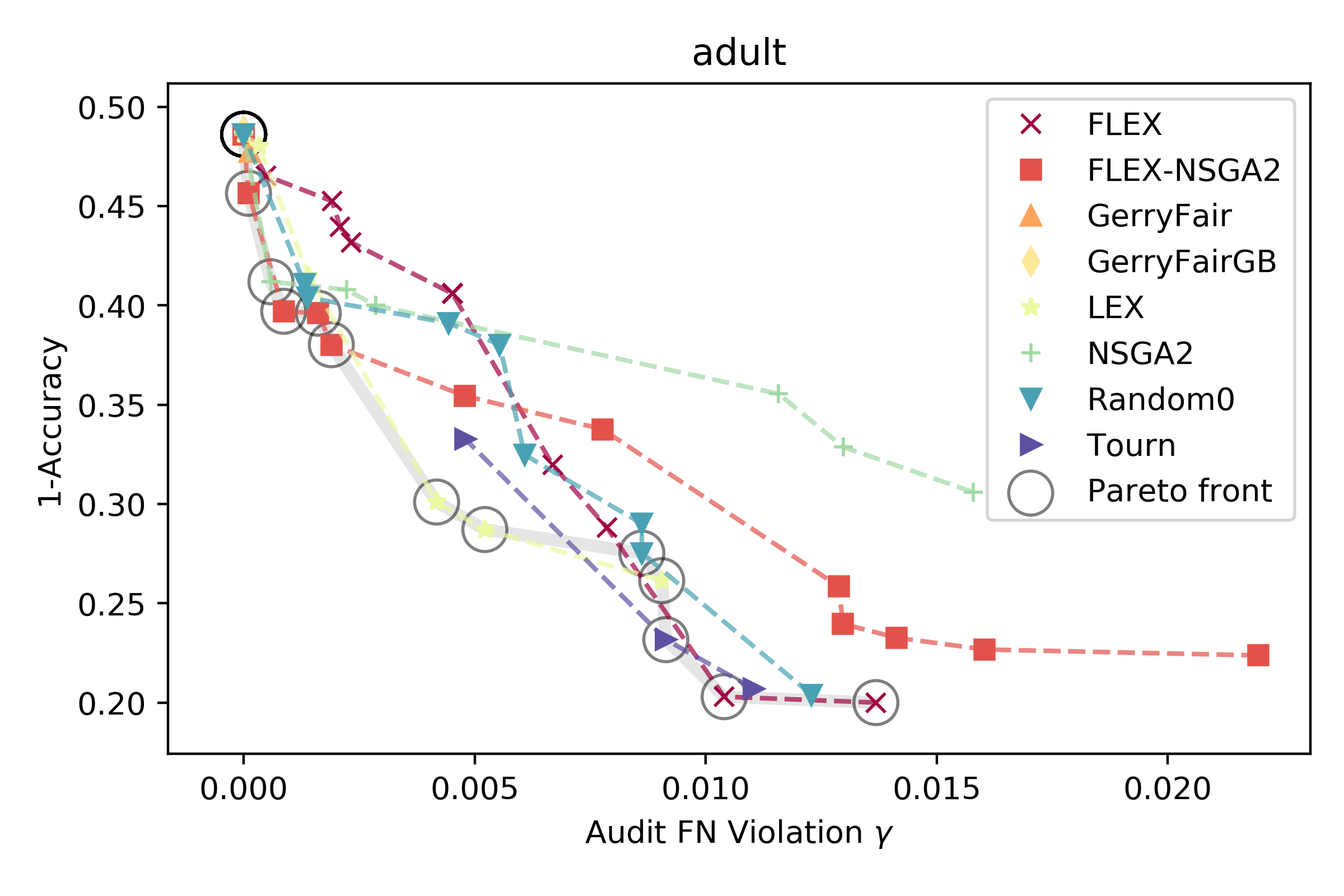
An example from [1] of different models and their trade-off between error and fairness on the adult dataset.
Relevant work:
1. La Cava, W. & Moore, Jason H. (2020). Genetic programming approaches to learning fair classifiers. GECCO 2020. Best Paper Award. [ACM] [arXiv]
Automating Digital Health
While artificial intelligence (AI) has become widespread, many commercial AI systems are not yet accessible to individual researchers nor the general public due to the deep knowledge of the systems required to use them. We believe that AI has matured to the point where it should be an accessible technology for everyone. The ultimate goal of this research area is to develop AI systems that automate the entire computational workflows of today’s data scientists. Doing will accelerate the analysis of complex data in the biomedical and health care domains.
Accessible, Automatic Data Science: github.com/EpistasisLab/pennai
Relevant work:
1. La Cava, W., Williams, H., Fu, W., & Moore, J. H. (2020). Evaluating recommender systems for AI-driven biomedical informatics. Bioinformatics. [open access] [arXiv]